
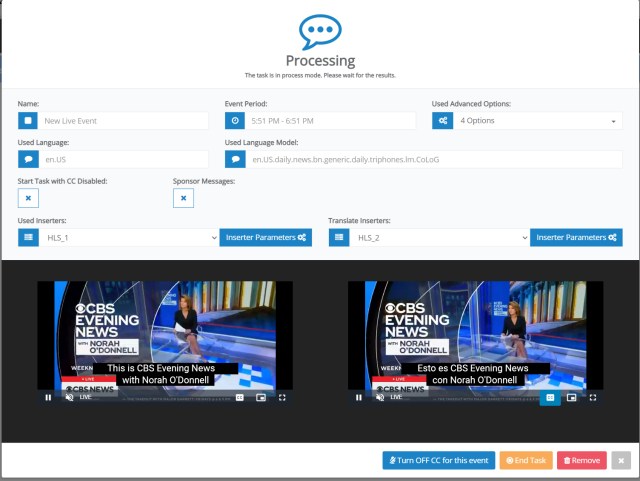
In a globalized world, there is growing demand for subtitling in different languages, not just in European or APAC markets, but also for North America, where acceptance and demand for Spanish programming is growing rapidly, and not just among Spanish-speaking communities.
So, not only is it necessary to present same-language captioning, but also translation. Due to the large volume of VOD shows and the nature of live news casts, the most cost-effective solution for TV stations and network groups is a reliable Automatic Speech Recognition (ASR) system, one which guarantees FCC compliance, high accuracy, low latency and native input formats that won’t interfere with existing IT infrastructures.
Audimus.Media is a VoiceInteraction product for Automatic Closed Captioning, available in over 30 languages and supporting English-Spanish and Spanish-English translation. The output includes automatic punctuation, capitalization and denormalization, with the possibility of encoding captions into video streams and captions reusability for VOD. This AI-driven platform currently empowers hundreds of television stations with 24/7 automatic closed captions. With a growing market-share worldwide, reaching 96 million homes in the US alone, Audimus.Media is becoming the standard on closed captioning as the benchmark solution.
VoiceInteraction is a company dedicated to speech processing technologies, with a varied product offering for the broadcast industry and other sectors. Our platforms rely on our proprietary ASR engine, AUDIMUS. Constantly evolving, it allows for highly customizable speech processing tasks in real-time, as well as post-recording workflows in multiple languages. Recently, automatic translation engine was added, the ideal addition to bilingual programming and regional shows that benefit from presenting the closed captioning and the translation on top.
Automatic Speech Recognition relies on acoustic and textual language models, streamlined through machine learning algorithms. VoiceInteraction manages the entire process when creating new models and refining supported languages, by analyzing annotated data and developing a pipeline for daily vocabulary updates. This results in language models for specific regional accents, ensuring better quality results, suited for a diverse market.
Recently, the team has been developing Korean, Russian and Turkish, important additions to our current language offering. Our R&D department tackles other complex issues daily, such as added accuracy for speaker recognition, segmentation and change of language model.
VoiceInteraction has been continually developing its core speech processing technology, while also expanding its coverage to new production and distribution workflows. Adding to an advanced new decoding strategy that allows for increased accuracy in unprepared speech, speech translation is now produced for live sources, enabling multiple subtitle languages per source stream. Our underlying proprietary speaker identification and language identification modules were overhauled, for new classifications produced with lower latency and higher accuracy.
To cope with market specificities, VoiceInteraction has been expanding the native formats that can be produced and sent as a contribution to MPEG-TS multiplexers or muxed by Audimus.Media into a MPEG-TS stream: DVB-Teletext, DVB-Subtitling, ARIB B24, ST 2038:202, and ETSI EN 301 775. New supported transport protocols were also added: Secure Reliable Protocol (SRT) and Reliable Internet Stream Transport (RIST) can be used as input or output.
Keeping a close eye on industry shifts and ever-changing needs, the platform will accompany stations as they transition from SDI to IP-based workflows, supporting both types of inputs. VoiceInteraction had these recent efforts recognized by the Broadcast & Media industry, as Audimus.Media was recently awarded Best of Show at both NAB Show and IBC in Amsterdam.
